
1. HOL 사전 준비
1-1) SSMS(SQL Server Management Studio) 설치
- 설치하기 위해서는 여기를 클릭해주세요.
1-2) HOL을 위한 csv 데이터 파일 준비
2. HOL 개요
2-1) HOL 개요
- Azure DataFactory를 이용해서 On-Prem의 데이터를 이관해 ODS에 적재
- Azure DataFactory를 이용해서 ODS의 데이터를 변환 후 DW에 적재
2-2) Architecture



2-3) HOL 진행 순서

3. 용어
3-1) 용어 정리
- HOL을 진행하기 전 용어에 대해 알아보고 진행하도록하겠습니다.
1. Linked Service
저장소의 접근 정보를 담고있는 리소스
예시) 통합 런타임 정보, SQL인증 형식 ID/PW
2. Dataset
Linked Service 기반의 접근 정보를 토대로, 저장소의 테이블(데이터) 정보를 담고있는 리소스
예시) Linked Service 통합 런타임 정보 테이블 정보
3. DataFlow Activity
데이터 변환을 위한 Job의 집합
예시) Select, Look up, Split 등
4. Activity 활동
데이터에 관련된 일련의 과정
예시) Data Copy, Data Flow, Notebook, Azure Function 등
5. Pipleline
Activity의 집합, 정의된 과정이나 Activity를 실행시키기 위한 개체
4. 리소스 배포
portal.azure.com으로 접속해서 로그인이 가능한 상태에서 HOL을 진행합니다.
4-1) 리소스 그룹 배포
- portal.azure접속 후 전역검색에 '리소스그룹'을 검색 후 서비스를 배포합니다.

4-2) Azure SQL Server & Database 배포
- portal.azure접속 후 전역검색에 'SQL Server'을 검색 후 서비스를 배포합니다.
- ODS용 Azure SQL Server 배포

- DW용 Azure SQL Server 배포
위와 같이 동일한 방식으로 SQL 인증을 통해 접속이 가능하도록 Azure SQL Server를 생성합니다. - Azure SQL Server 배포 확인

- 각 Azure SQL Server에 해당하는 Database 생성



- DW Database를 만든 방식과 동일하게 ODS Database를 만듭니다.
- DW, ODS Azure SQL Database 배포 확인

4-3) Azure DataFactory 배포
portal 전역 검색에 '데이터팩터리'를 검색해서 서비스를 배포합니다.
- Azure DataFactory 배포


- Azure DataFactory 배포 확인

4-4) Managed Private endpoint
- 상기 내용으로 생성한 Azure SQL Server는 방화벽을 적용했기 때문에 Client IP를 제외하고 접근이 불가능한 상태입니다. Azure Service가 접근하기 위해서는 방화벽의 예외 옵션을 활성화 시켜줘야합니다.
- 여기서는 Managed Private endpoint를 통해서 연결이 될 수 있도록 구성하겠습니다.


- Managed Private endpoint 생성하기
Azure DataFactory 리소스 >> Studio 시작하기 클릭 >> 사이드바 '관리' 클릭 >> Managed Private endpoint 새로만들기
- 새 연결된 서비스로 Azure SQL Server를 선택합니다.

- 새 연결된 서비스 설정을 진행합니다.

- Managed Private endpoint 생성을 확인합니다.
현재는 Provisioning 상태입니다. 왜냐하면 연결 예정인 Azure SQL Server로 이동 후, 별도의 승인 작업이 필요하기 때문입니다. - Azure SQL Server에서 Managed Private endpoint 승인 작업을 진행합니다

- 정상적으로 승인이 되었는지 확인합니다.


5. Azure DataFactory 설정
5-1) Azure DataFactory의 Linked Service 설정을 진행합니다.
- Azure DataFactory Studio >> sidebar manage >> Linked Service >> 새로만들기

- 새 연결된 서비스 설정 진행
대화형 작성 기능은 관리형 Virtual Network 내부에서 연결 테스트/데이터 찾아보기 및 미리보기/매개변수 가져오기/스키마 가져오기 같은 기능에 대한 작성 중에 사용됩니다.


'통합 런타임을 통해 연결' 구성을 완료한 후 '새 연결된 서비스'에 대해 나머지 값들을 설정합니다.
아래 '연결 테스트' 진행 후 연결 성공 표시가 나오면 만들기를 클릭하면됩니다.


!! 주의 : Managed Private Endpoint와 Linked Service는 DW Server와 ODS Server 둘 다 생성해줍니다.
Linked Service 연결 테스트 성공 까지 완료 한 후 다음 과정을 진행합니다.


6. SSMS 연결 및 CSV 파일 Import
해당 문항에서는 SSMS를 통해서 CSV 파일을 Azure SQL Server (ODS)로 Import 하는 과정을 실습하겠습니다.
6-1) SSMS 연결을 진행하겠습니다.
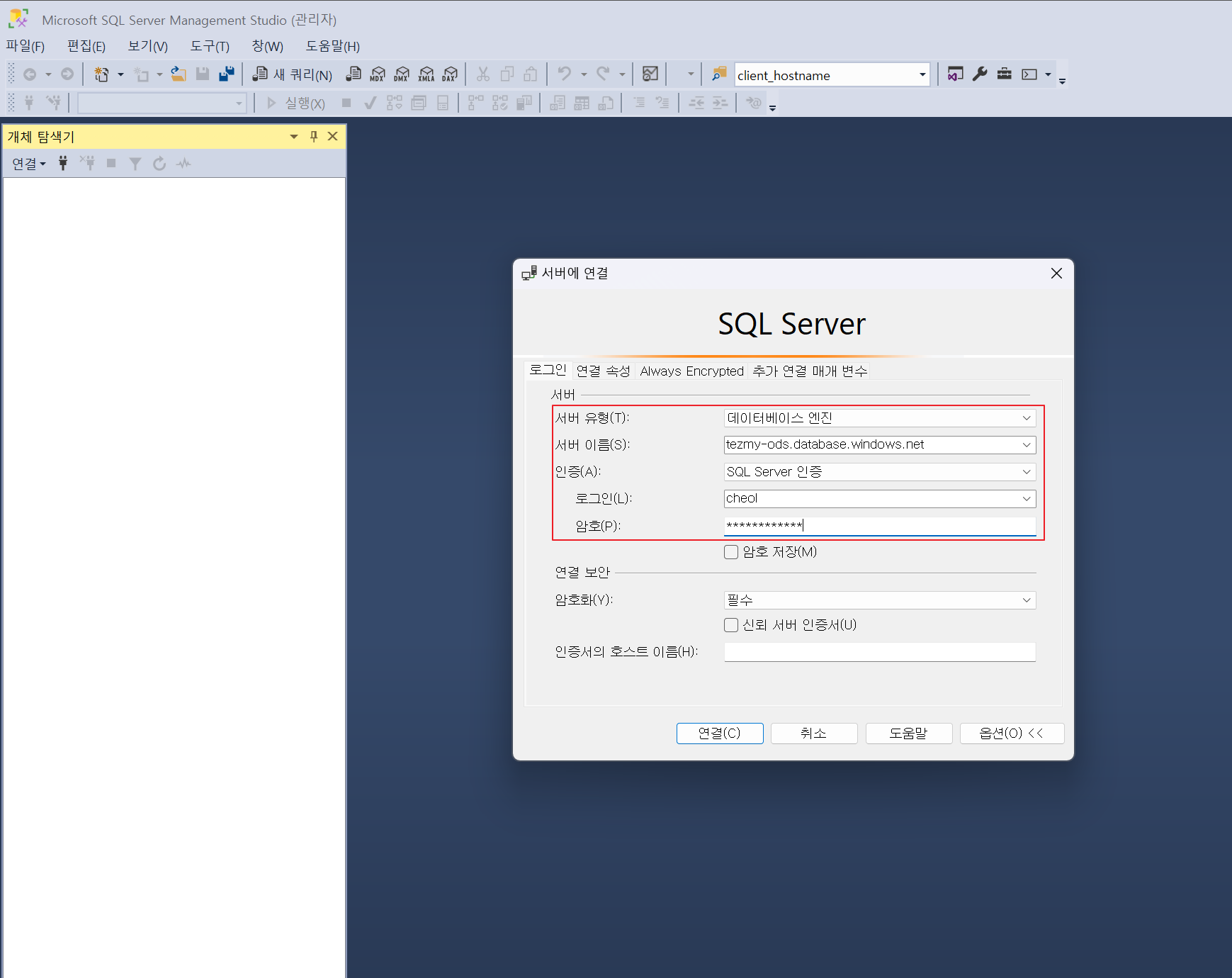

6-2) CSV파일을 SSMS를 통해서 ODS SQL Database에 업로드하도록 하겠습니다.



- 아래 이미지 과정에서 해당 옵션을 비활성화를 진행합니다.

- 아래 과정에서 Column명칭과 Data Type 등 이미지와 동일하게 설정합니다.


- 위와 같은 방식으로 다른 CSV 파일 또한 SSMS을 통해서 ODS SQL Database에 Import를 진행합니다.
Column값과 Data Type을 설정할때 아래 이미지를 참고해서 진행합니다.
- country_lookup.csv
- dim_data.csv 파일

- ODS Database에 CSV파일이 정상적으로 Import 된 것을 확인합니다.

7. Data Flow
7-1) Raw Data Overview
- hospital_admissions 데이터 파악
일간 및 주간, 일반 병실 및 중환자실의 데이터가 단일 column에 혼재
따라서, 일간/주간 기준으로 테이블 분리 및 일반/중환자실로 column 분리 필요

- 집계 보고된 날짜의 연도(year)와 주(week)차 정보만 존재함
따라서, 직관적인 날짜 확인이 가능하도록 'dim_data' 테이블과 join을 통해 개선 필요

- 데이터 분석 관점에서 URL정보는 필요 없으므로 column삭제를 통해 개선 예정

- Main Data(hospital_admissions)의 주차 정보(year_week) join에 활용

- Main Data(hospital_admissions)의 국가정보(country) 기준, 국가코드와 인구정보 Lookup

- 국가에 대한 추가 정보를 Lookup하기 위해 활용

- 단일 Column에 혼재된 정보를 일반 및 중환자 기준으로 분리

- 일간 기준, "data" column을 활용하고 명칭 변경 (reported_data)
주간 기준, "year_week" column을 활용하고 명칭 변경 (reported_year_week)

- 일반 및 중환자 기준을 분리함에 따라, 해당 기준에 맞는 수치 활용

- 각 수치에 대한 출처를 확일할 수 있어야하기 떄문에, 해당 Column 활용

- url 정보는 필요 없기때문에 해당 column 제거

- 주간 기준, 정보개선을 위해 "dim_date" Table을 이용해 Lookup

- "country" column기준, 국가 코드와 인구 정보를 Lookup

7-2) Dataset 생성
- DataSet 생성
Portal >> Azure DataFactory >> 만든 이 >> "+" 클릭 >> 데이터 세트


- 속성 설정
속성을 설정하는 도중 테이블 이름이 보이지 않는다면 새로고침 진행 후 확인합니다.

- '스키마 가져오기'에서 연결/저장소에서 가져오기가 실패한다면 없음으로 먼저 설정 해놓고 추후에 스키마 가져오기를 진행합니다.
데이터 세트 >> 해당 데이터세트 클릭 >> 스키마 >> 스키마 가져오기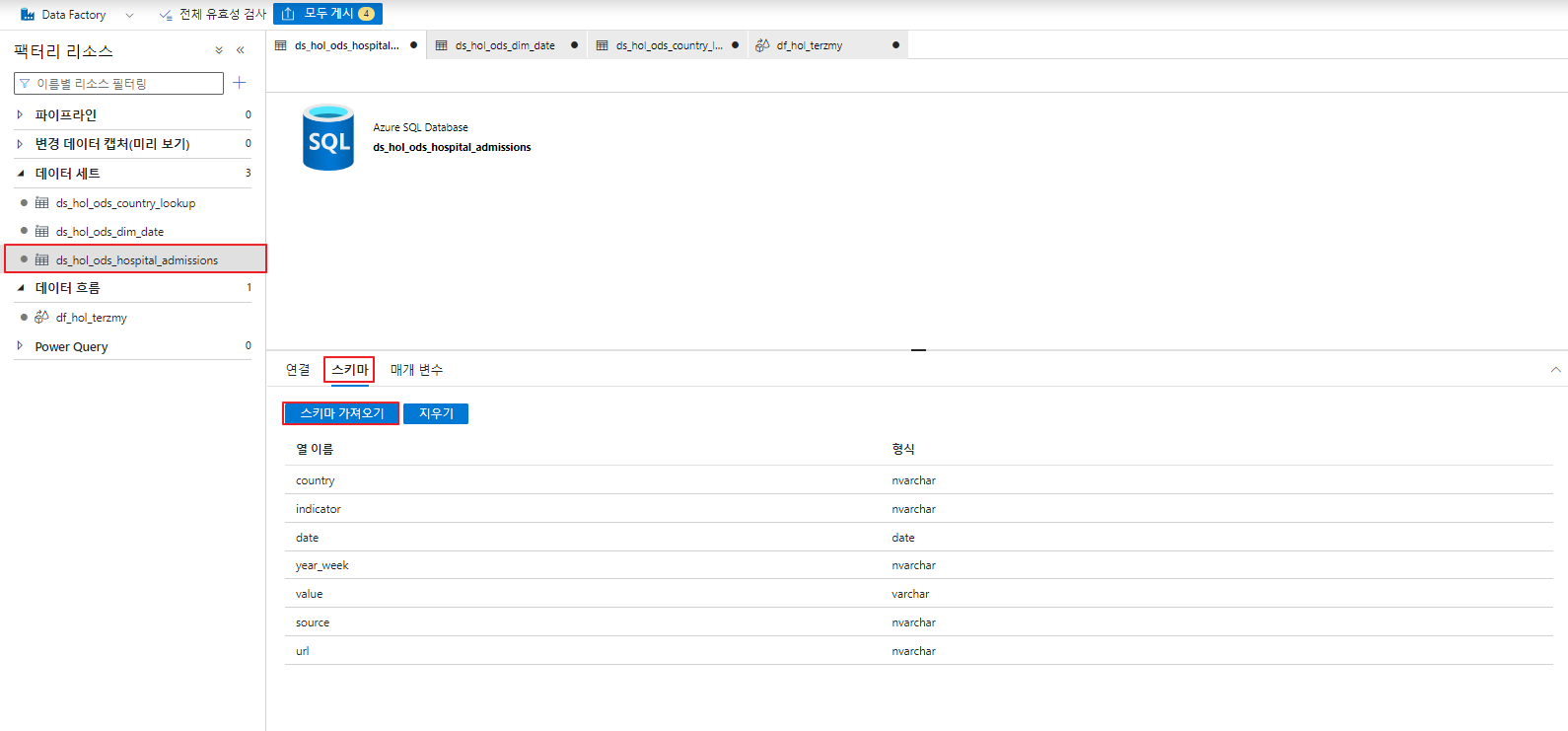
- Dataset 생성 후 데이터 미리보기

!!주의 : Dataset을 생성하는 과정을 동일하게 dim_data, country_look에 대해서도 진행합니다.

!!주의 : Dataset을 생성하는 과정을 동일하게 ds_hol_dw_daily_hospital_admissions, ds_hol_dw_weekly_hospital_admissions에 대해서도 진행합니다.


7-3) DataFlow 생성
- DataFlow 생성
Portal >> Azure DataFactory >> 만든 이 >> "+" 클릭 >> 데이터 흐

- 기본 설정
속성 >> 이름 추가 >> 데이터 흐름 디버그 활성화


- DataFlow 소스 추가 - HospitalAdmissions
소스 추가 >> 출력 스트림 이름 추가 >> 데이터 세트 설정 >> 프로젝션


- 소스에 대한 스키마를 덮어쓰기를 진행합니다.
프로젝션 >> 스키마 덮어쓰기

- 스키마 덮어쓰기 후 데이터 미리보기 탭으로 넘어갑니다.
데이터 미리보기 탭으로 넘어갔을 때 에러가 발생한다면 Linked Service를 레거시 모델로 변경해야합니다.
아래 에러와 비슷하게 나오면 레거시로 변경해야합니다. (아래 에러는 stackoverflow의 예시입니다.)
Spark job failed: {
"text/plain": "{\"runId\":\"94405efb-4fd6-449e-aa7f-e4396f1db87f\",\"sessionId\":\"93dd501b-ac03-4c93-8773-36058e06b8a0\",\"status\":\"Failed\",\"payload\":{\"statusCode\":400,\"shortMessage\":\"com.microsoft.dataflow.broker.MissingRequiredPropertyException: server is a required property for AzureSqlDatabase1.\\ncom.microsoft.dataflow.broker.PropertyNotFoundException: Could not extract value from AzureSqlDatabase1\",\"detailedMessage\":\"Failure 2024-05-17 07:10:36.828 failed DebugManager.processJob, run=94405efb-4fd6-449e-aa7f-e4396f1db87f, errorMessage=com.microsoft.dataflow.broker.MissingRequiredPropertyException: server is a required property for AzureSqlDatabase1.\\ncom.microsoft.dataflow.broker.PropertyNotFoundException: Could not extract value from AzureSqlDatabase1\"}}\n"
} - RunId: 94405efb-4fd6-449e-aa7f-e4396f1db87f

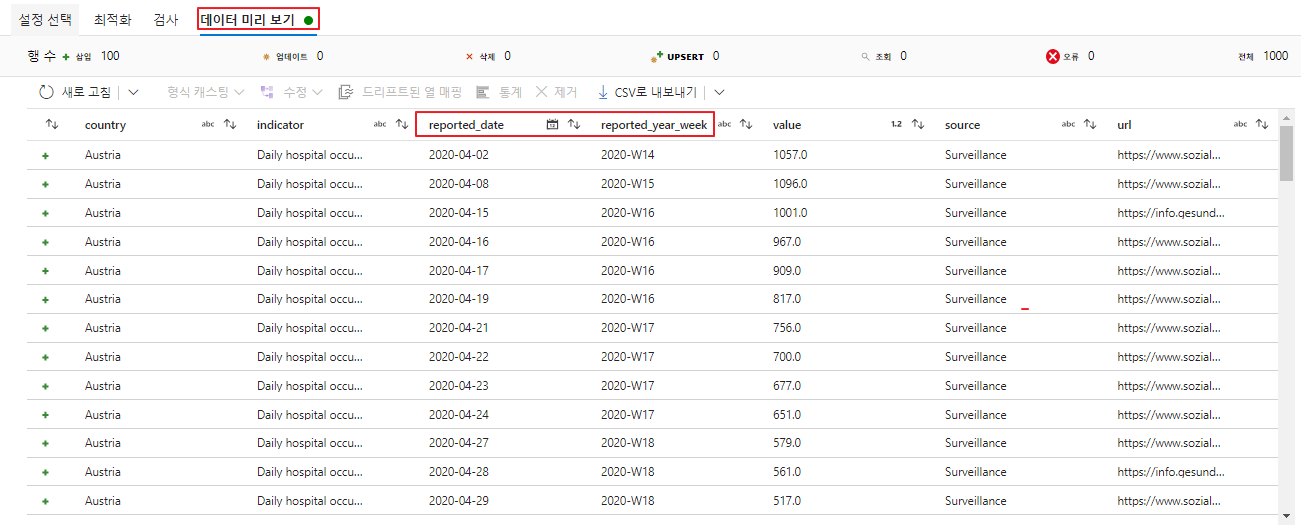
- DataFlow 생성 - 선택(select)
소스 추가 후 해당 소스에 대한 선택 흐름 생성
선택(select) 액티비티는 Column을 선택해 삭제허거나 이름 등을 변경할 수 있습니다.


- 선택(select) 액티비티에 대한 검사 및 데이터 미리보기를 확인합니다.

- DataFlow 소스 추가 - CountryLookup
HospitalAdmissions 소스에 존재하는 Country 컬럼을 기준으로 국가코드와 인구 정보를 조회(Lookup)할 예정이기 때문에 소스를 추가하는 작업입니다.
이처럼, 데이터 플로우에서는 다양한 소스를 이용해 데이터르 변환 작업이 가능합니다.

- DataFlow 생성 - 조회(Lookup)
조회(Lookup) 액티비티는 HospitalAdmissions 소스의 country 컬럼 데이터를 기준으로 CountryLookup 소스의 country 컬럼의 값과 일치하면, countryLookup 소스의 데이터를 가져오도록 하는 역할을 수행합니다.

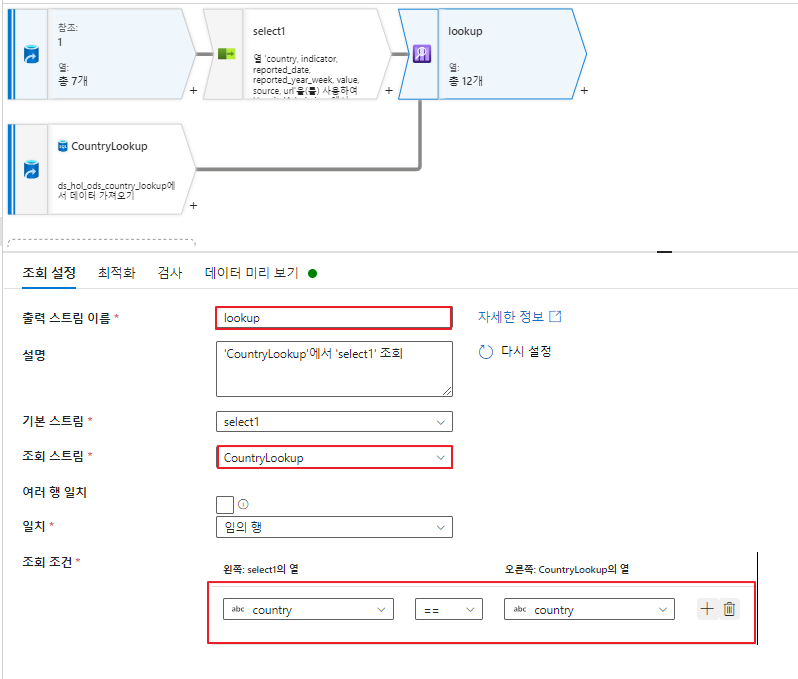
- Lookup에 대한 검사 및 데이터 미리 보기
country 컬럼을 기준으로 HospitalAdmissions 소스에 countrylookup 소스의 컬럼들이 추가된 모습을 확인할 수있습니다.


- 중요도가 상대적으로 적은 continent 컬럼을 삭제하기 위해 선택(select) 액티비티를 통해 제거하도록 하겠습니다.


- continent 컬럼이 삭제된 것을 볼 수 있습니다.

- DataFlow 생성 - 조건부 분할
분할 조건으로 다음 정보를 입력해 넣습니다.
다음과 같이 설정을 진행하면 조건식에 부합하는 데이터는 "weekly"라는 이름을 가진 스트림으로 분리됩니다.
조건식에 부합하지 않는다면 "Daily"라는 스트림으로 분리됩니다.
indicator=='Weekly new hospital admissions per 100k' || indicator == 'Weekly new ICU admissions per 100k'
## indicator 컬럼 값이 Weekly new hospital admissions per 100k 경우 또는 Weekly new ICU admissions per 100k 인 경우 분할

- 다음은 조건부 분할로 인해서 분리된 스트림을 보여줍니다.


- DataFlow 소스 생성 - DimDate

- DimDate의 파생열 생성합니다.
열(Column) 영역에 커서를 두고 ecdc_year_week라고 직접 입력합니다.
그 후, 식 작성기 열기를 클릭합니다.

- 식 작성기 열기에서 year 목록을 찾아 클릭합니다.
year를 클릭한 후 식에서 +'-W'+ 을 입력합니다.

- 그 후, 식 요소의 함수를 클릭하고 식 값에 lpad를 입력하여 함수를 가져옵니다.

- 식 요소의 모두를 클릭한 후 week_of_year를 클릭합니다.

- 아래 내용을 추가로 입력하고 새로고침을 진행합니.

- 작성된 식으로 인해서 출력된 컬럼을 볼 수 있습니다. 확인 후 저장 및 완료를 클릭합니다.


- DataFlow Dim Date의 파생열을 검사 및 데이터 미리보기를 진행합니다.


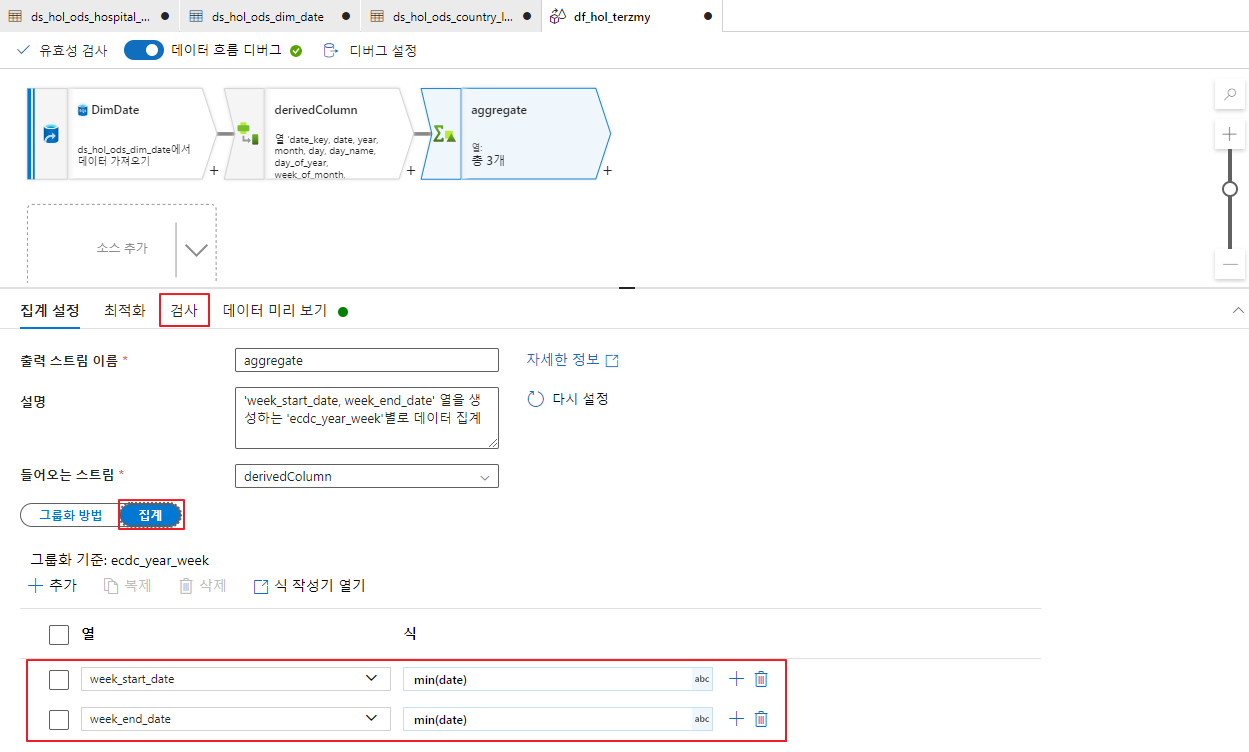
- DataFlow Dimdate 집계 생성
집계 액티비티는 특정한 컬럼을 기준으로 다양한 집계 함수를 사용해 컬럼을 추가할 수 있는 액티비티입니다.
주간 정보에 대한 직관적인 정보를 얻기 위해 시작 및 종료 날짜를 구해보도록 하겠습니다.
- 그룹화 방법으로 ecdc_year_week를 선택합니다.

- 집계는 아래 이미지와 같이 설정합니다.
집계 : week_start_date, week_end_date
함수 : min(date)


- 검사 및 데이터 미리 보기를 진행합니다.


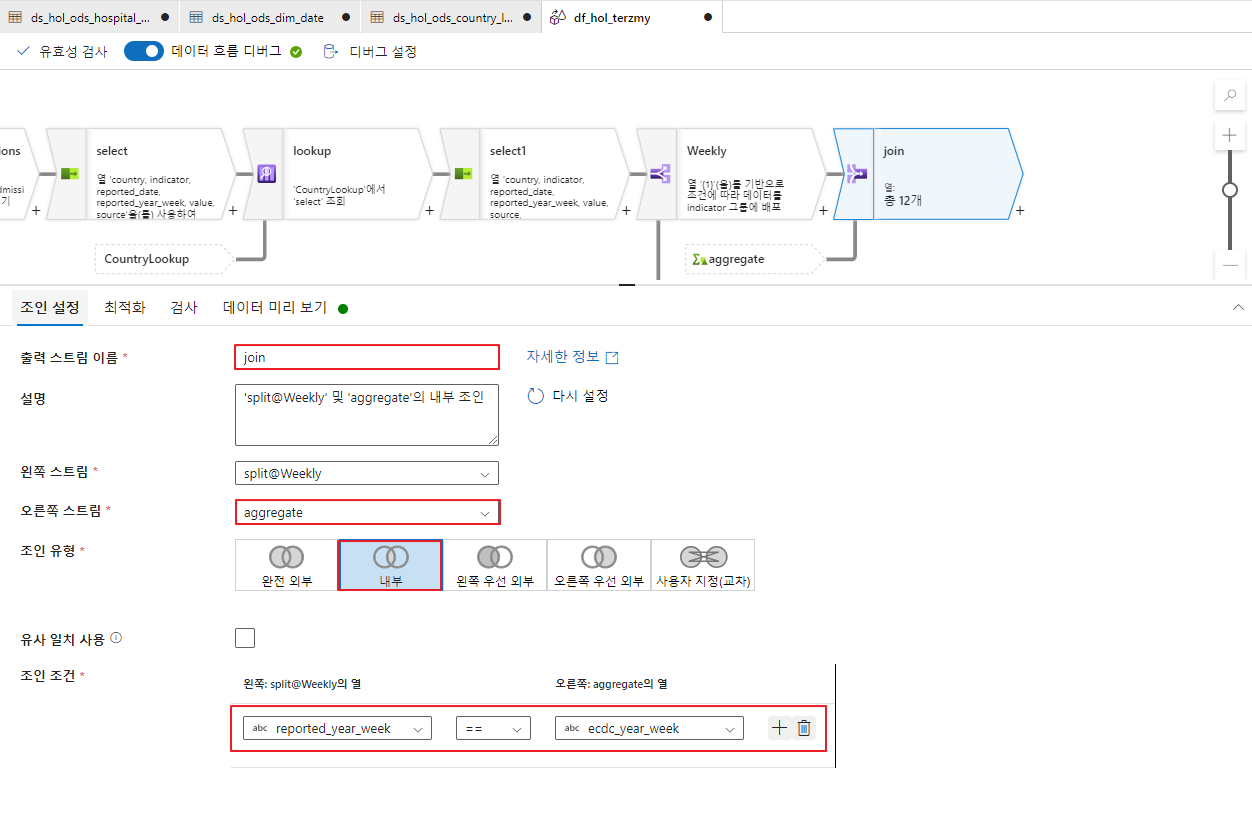
- DataFlow 생성 - 조인
조인 액티비티는 테이블 간 공통되는 데이터의 집합에 따라 변환할 수 있는 액티비티입니다.
이전 과정을 통해 주차에 대한 세부 정보를 얻었으므로 weekly 스트림과 aggregate 스트림간 교집합에 속하는 데이터를 얻을 수 있습니다.
- Join 생성
조인 유형 : 내부
조인 조건 : reported_year_week == ecdc_year_week

- 조인에 대한 검사 및 데이터 미리 보기를 진행합니다.


- DataFlow 생성 - 피벗
- 첫번째 피벗 생성 (weekly)

- 피벗 설정 탭으로 가서 그룹화 기준의 열 추가와 출력 스트림 이름을 설정합니다.

- 피벗 키 탭으로 이동하여 피벗 키 및 값에 대한 설정을 진행합니다.

- 피벗된 열 탭으로 이동하여 열이름 패턴을 선택하고 열 정렬을 수평으로 설정합니다.

- 피벗 열 이름 생성
열 이름 : count
함수 : sum(value)

- 피벗에 대한 검사 및 데이터 미리보기를 진행합니다.


- 두번째 피벗 생성 (Daily)
Weekly 피벗과 동일하게 출력 스트림 및 그룹화 기준 열 설정을 진행합니다.

- 마찬가지로 피벗 키 탭으로 이동하여 피벗 키 및 값을 설정합니다.

- Daily 피벗 함수와 똑같이 설정을 진행합니다.
열 이름 : count
함수 : sum(value)

- 피벗된 열 탭으로 이동하여 열 이름 패턴을 선택하고 열 정렬을 수평으로 설정합니다.

- 검사 및 데이터 미리 보기를 진행합니다.


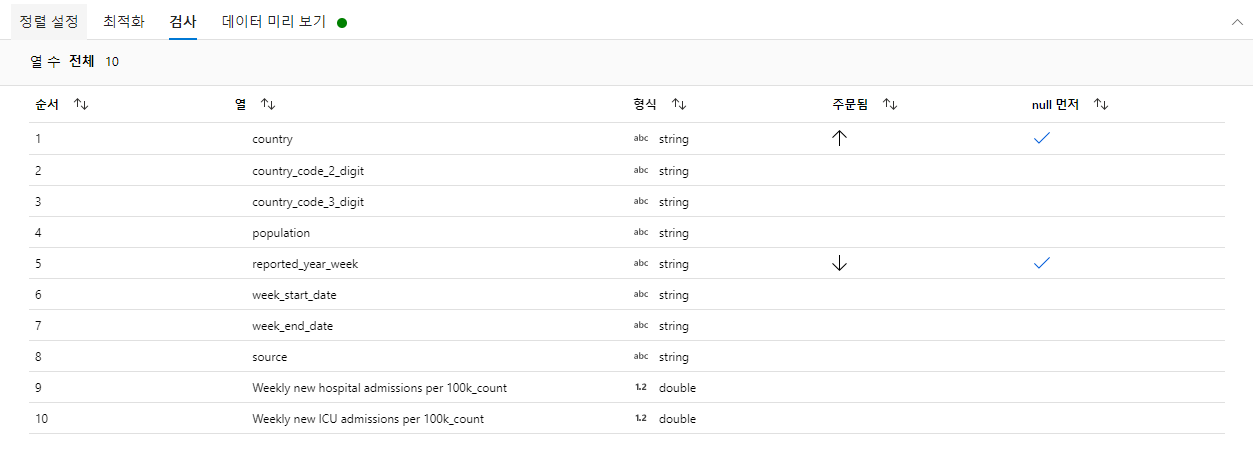
- DataFlow 생성 - 정렬
정렬 액티비티는 데이터를 오림차순 및 내림차순으로 Sort 할 수 있는 액티비티입니다.

- weekly 정렬
날짜는 최신부터 확인할 수 있도록 내림차순 기준을 부여했습니다.
국가명은 ABC 순서로 확인할 수 있도록 오름차순 기준을 부여했습니다.

- 정렬에 대해 검사 및 데이터 미리 보기를 진행합니다.

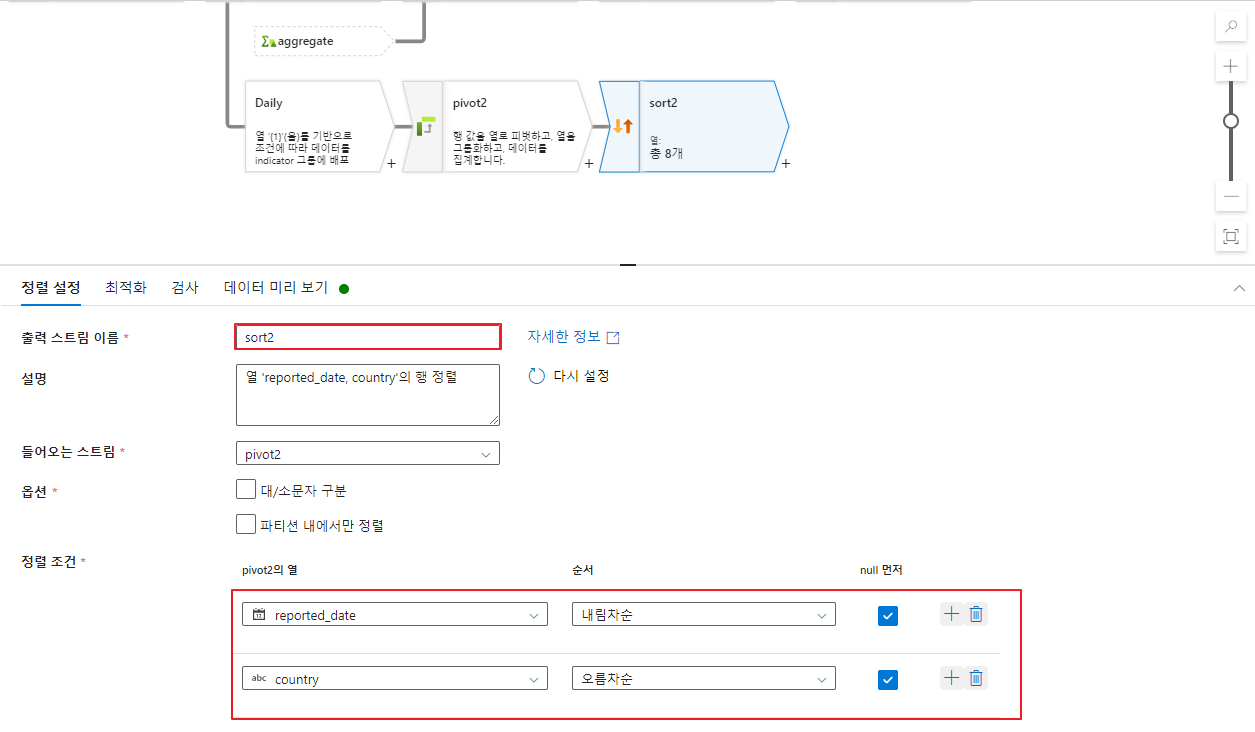
- 두번째 정렬 (Daily)
앞서 설정했던 값들과 동일하게 진행합니다.
- DataFlow 생성 - 선택
- 정렬의 열을 아래와 같은 그림으로 순서를 정하고 값을 지정합니다.
Weekly new ICU admissions per 100k_count를 new_icu_occpuancy_count로 변경
Weekly new hospital admissions per 100k_count 을 new_hospital_occupancy_count로 변경

- 정렬 데이터 흐름에 대해서 검사 및 데이터 미리보기를 진행합니다.


- DataFlow 생성 - 싱크
싱크 액티비티는 변환 작업이 완료된 데이터를 어디에 저장할 것인지 정의하는 액티비티입니다.
데이터 플로우에서 반드시 필요한 요소 중 하나입니다.
- 첫번째 싱크 생성 (weekly)
- 출력 스트림 이름을 설정하고 기존에 생성해놨던 DW 데이터 시트를 선택합니다.

- 두번째 싱크 생성 (Daily)

8. 데이터 파이프라인 생성 및 실행
8-1) 데이터 파이프라인 아키텍처

8-2) 데이터 흐름 생성 후 모두 게시
데이터 흐름 이름 : df_hol_terzmy


8-3) 트리거 추가 >> 지금 트리거
트리거를 시작해서 파이프라인이 정상적으로 작동하는지 확인합니다.
정상적으로 작동한다면 ODS의 소스 데이터가 파이프라인을 통해서 변환이 일어나고 DW에 데이터가 적재되게 됩니다.


8-4) SSMS를 통해서 DW에 적재되어있는 데이터를 확인합니다.

'Azure' 카테고리의 다른 글
| Private Link를 통한 Azure PostgreSQL의 Private Networking (0) | 2024.07.03 |
|---|---|
| [Study] Azure PostgreSQL (0) | 2024.07.03 |
| Azure Private DNS Resolver (0) | 2024.06.18 |
| Azure AppService 사용자 지정 도메인 (0) | 2024.06.17 |
| [Study] DTU와 vCore 차이점 (0) | 2024.06.13 |