이번 블로그에서는 테라폼을 이용한 Azure 고성능 컴퓨팅 인프라 환경을 구축해보는 연습을 진행하겠습니다.
고성능 컴퓨팅의 경우, CycleCloud를 이용해서 구축할 예정입니다.
그리고 고성능 컴퓨팅에 맞는 파일 시스템 스토리지 구축에는 Lustre를 사용하도록 하겠습니다.
먼저, Cyclecloud와 Lustre가 간단히 어떤 역할을 하는지부터 설명드릴게요!
CycleCloud란?
Azure에서 HPC 클러스터를 손쉽게 만들고 관리하며 최적화할 수 있도록 도와주는 클러스터 오케스트레이션(Orchestration) 도구입니다. 계산 작업을 직접 수행하는 것이 아니라, 계산 작업을 수행할 수많은 가상 머신(계산 노드)들을 지휘하고 통제하는 역할을 합니다.
CycleCloud는 Microsoft가 직접 인수하여 개발하는 공식 도구입니다. Azure Marketplace에 미리 구성된 가상 머신 이미지로 제공되므로, Terraform이나 포탈을 통해 간단하게 설치하고 즉시 사용할 수 있습니다. Azure의 모든 VM 종류, 스토리지, 네트워킹 서비스와 완벽하게 통합되어 작동합니다.
Lustre란?
수백, 수천 개의 서버(계산 노드)가 동시에 하나의 저장소에 엄청난 양의 데이터를 읽고 쓰는 **대규모 병렬 파일 시스템(Parallel Filesystem)**입니다. 일반적인 네트워크 스토리지(NAS)가 1차선 도로라면, Lustre는 수십, 수백 차선의 고속도로와 같습니다.
과거에는 Lustre를 사용하려면 전문가가 직접 여러 서버를 설치하고 복잡하게 구성해야 했습니다. 하지만 이제 Azure는 Azure Managed Lustre라는 **완전 관리형 서비스(PaaS)**를 제공합니다. 사용자는 Terraform 코드 몇 줄만으로 고가용성이 보장된 Lustre 클러스터를 몇 분 만에 배포할 수 있습니다. 특히, Lustre의 고속 캐시와 Azure Blob 스토리지의 저렴한 대용량 저장소를 자동으로 연동(HSM)하는 기능은 Azure만의 강력한 장점입니다.
그럼, 이제 아키텍처를 구성하고 테라폼을 이용해서 인프라를 배포하도록 하겠습니다.
아키텍처
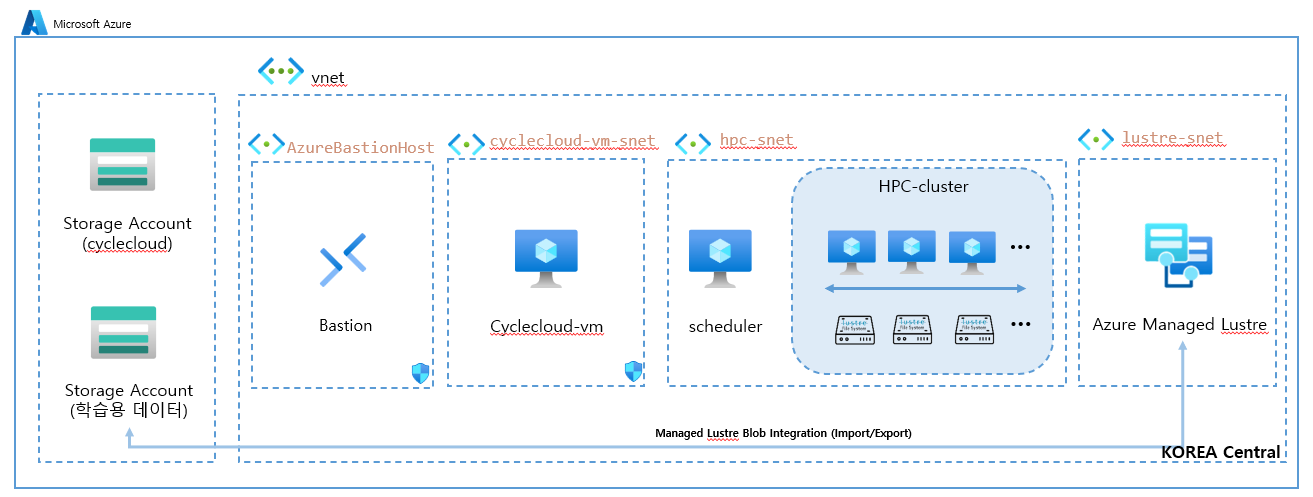
1. 네트워크 인프라 (Networking)
- vnet (가상 네트워크): 모든 리소스가 배포되는 격리된 프라이빗 네트워크 공간입니다.
- Subnets (서브넷): VNet 내부를 기능별로 나눈 작은 네트워크 구역입니다. 각 구역은 NSG(네트워크 보안 그룹)를 통해 서로 다른 보안 규칙을 적용받을 수 있어 보안과 관리가 용이해집니다.
- AzureBastionSubnet: Azure Bastion 서비스 전용으로 사용되는 특별한 서브넷입니다.
- cyclecloud-vm-snet: CycleCloud 관리 서버를 위한 서브넷입니다.
- hpc-snet: 실제 계산 작업을 수행할 스케줄러와 HPC 클러스터를 위한 서브넷입니다.
- lustre-snet: 고성능 파일 시스템인 Lustre를 위한 서브넷입니다.
2. 관리 및 오케스트레이션 (Management & Orchestration)
- Bastion : 인터넷에서 내부 가상 머신들(CycleCloud, Scheduler 등)로 안전하게 접속할 수 있도록 해주는 보안 접속 서비스(Jump Box)입니다. 모든 VM의 SSH(22) 포트를 인터넷에 직접 노출하는 대신, Bastion이라는 단 하나의 강화된 관문을 통해서만 접근하도록 하여 보안을 크게 향상시킵니다. 본 과정에서는 특정 온프렘 Public IP에서만 Bastion을 통해서 Cyclecloud 가상머신에 접근이 가능하도록 구성합니다.
- Cyclecloud-vm (클러스터 지휘자): 이 아키텍처의 오케스트레이터(Orchestrator)입니다. Scheduler에 제출된 작업의 양을 감시하다가, 작업이 많아지면 HPC-cluster에 계산 노드(VM)를 자동으로 생성하고, 작업이 끝나면 노드를 자동으로 삭제하여 비용을 최적화하는 핵심적인 역할을 합니다.
3. 계산 리소스 (Compute Resources)
- Scheduler (작업 스케줄러): 사용자가 HPC 작업을 제출하는 진입점입니다. 제출된 작업들을 큐(Queue)에 쌓고 순서를 관리하며, "지금 이만큼의 계산 자원이 필요해!"라고 CycleCloud에게 알려주는 역할을 합니다.
- HPC-cluster (계산 노드): 스케줄러의 요청에 따라 CycleCloud가 생성하는 수많은 가상 머신들입니다. 이 노드들이 병렬로 연결되어 복잡한 시뮬레이션, 데이터 분석, 렌더링 등 실제 연산을 수행하는 '일꾼' 역할을 합니다.
4. 스토리지 (Storage)
- Storage Account (CycleCloud): CycleCloud 서버 자체의 설정, 소프트웨어 설치 파일, 운영 데이터 등을 저장하는 데 사용되는 스토리지 계정입니다.
- Storage Account (학습용 데이터): HPC 클러스터가 처리해야 할 원본 데이터(예: 연구 데이터, 시뮬레이션 입력값, 렌더링 소스 파일)를 장기간 저렴하게 보관하는 '데이터 레이크' 또는 '영구 저장소' 역할을 합니다.
- Azure Managed Lustre (고성능 작업 공간): HPC 클러스터가 계산을 수행하는 동안 데이터를 읽고 쓰는 초고속 작업 공간(Scratch Space)'입니다. Blob Integration을 통해 '학습용 데이터' 스토리지에 있던 원본 데이터를 Lustre로 빠르게 가져와(Import) HPC 클러스터가 초고속으로 처리한 후, 결과물을 다시 스토리지 계정으로 내보낼(Export) 수 있습니다.
프로젝트 구조
우선 코드 공유부터 해드리도록 하겠습니다.
# github reppo
https://github.com/qpsaone2/terraform-cyclecloud-lustre.git
테라폼 프로젝트 구조는 다음과 같습니다.
리소스별로 모듈화하여 루트 main.tf에서 호출하여 관리하도록 진행하였습니다.
tfstate 상태 파일의 경우, 테스트 환경으로 진행하는거라 편의상 Blob에서 관리하지 않고 로컬에서 관리하도록 하였습니다. 자세한 코드에 대한 설명은 주석으로 설명해놨습니다.
cheol@MZC01-CLOUDLSC0406:/mnt/c/code/terraform_code/hpc-project$ tree
.
├── README.md
├── main.tf
├── modules
│ ├── bastion
│ │ ├── main.tf
│ │ └── variables.tf
│ ├── lustre
│ │ ├── main.tf
│ │ └── variables.tf
│ ├── nsg
│ │ ├── bastion
│ │ │ ├── main.tf
│ │ │ └── variables.tf
│ │ ├── cyclecloud
│ │ │ ├── main.tf
│ │ │ └── variables.tf
│ │ └── lustre
│ │ ├── main.tf
│ │ └── variables.tf
│ ├── nsg_assoc
│ │ ├── main.tf
│ │ └── variables.tf
│ ├── rbac
│ │ └── lustre
│ │ ├── main.tf
│ │ └── variables.tf
│ ├── snet
│ │ ├── main.tf
│ │ └── variables.tf
│ ├── storage
│ │ ├── main.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ ├── vm
│ │ ├── main.tf
│ │ └── variables.tf
│ └── vnet
│ ├── main.tf
│ └── variables.tf
├── outputs.tf
├── terraform.tfstate
├── terraform.tfstate.backup
├── terraform.tfvars
├── variables.tf
├── variables_.copy.tf
└── versions.tf
테라폼 코드를 로컬로 받아와서 az login으로 azure에 로그인 후 배포를 진행합니다.
# 테라폼 프로젝트 초기화
terraform init
# 테라폼 플랜
terraform plan
# 테라폼 인프라 배포
terraform apply --auto-approve
1) 테라폼 프로젝트 초기화

2) 테라폼 plan 및 apply

3) 가상네트워크 및 서브넷 배포

4) 스토리지 계정 배포
5) Bastion 배포

6) Managed Lustre 배포

7) Cyclecloud 가상머신 배포


8) 전체 배포된 리소스 확인

이슈사항
1. 가상머신 생성 ( 추가적인 데이터 디스크 연결 )
처음에 우리는 최신 리소스인 azurerm_linux_virtual_machine을 사용하여 VM을 배포하려 했습니다. 이는 당연하고 올바른 시도였지만, CycleCloud 이미지의 특별한 요구사항 때문에 실패했습니다.
- 기술적 배경: azurerm_linux_virtual_machine 리소스는 사용 편의성을 위해 많은 부분이 추상화되어 있습니다. 데이터 디스크를 붙일 때는 VM을 먼저 생성한 후, azurerm_virtual_machine_data_disk_attachment 리소스를 통해 추가적인 단계로 디스크를 연결하는 방식을 사용합니다.
- 하지만 CycleCloud 마켓플레이스 이미지는 단순한 OS가 아니라, 최초 부팅 시점에 특정 설정(스크립트 실행 등)을 수행하는 '어플라이언스'입니다. 이 설정 과정에서 처음부터 데이터 디스크가 존재할 것을 기대합니다. VM 생성과 디스크 연결이 분리된 최신 리소스의 방식은 이 요구사항을 만족시킬 수 없었던 것입니다.
- 해결책과 교훈: 구형 리소스인 azurerm_virtual_machine은 storage_data_disk 블록을 지원합니다. 이 블록은 VM 생성 API를 호출할 때 OS 디스크와 데이터 디스크의 정보를 하나의 요청(Payload)에 모두 담아 보냅니다. 따라서 CycleCloud 이미지가 원하는 대로, VM이 생성되는 시점에 데이터 디스크가 이미 준비된 상태가 될 수 있었습니다.
제가 배포하기 위한 테스트에서는 azurerm provider 최신 버전(4.x)을 사용했습니다. 최신 버전을 사용하면서 azurerm_virtual_machine를 통한 데이터 디스크를 추가하기 위해서는 아래 내용에 대해서 환경변수 설정이 필요했습니다.
환경변수 설정을 하지 않는다면 terraform plan시 구독 ID를 읽어오지 못하는 에러가 발생했습니다.
(물론, az login 되어있었는데도 말이죠..)
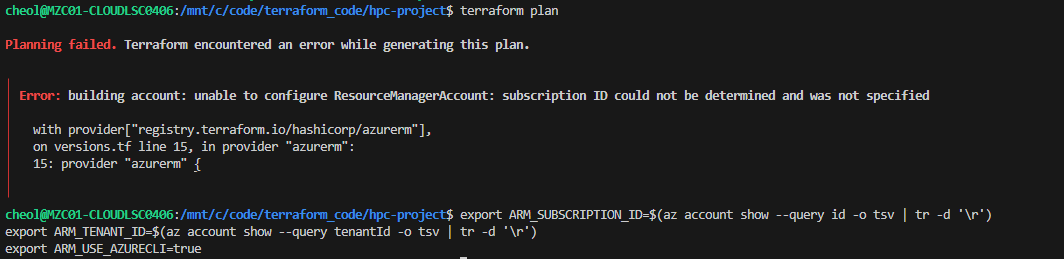
export ARM_SUBSCRIPTION_ID=$(az account show --query id -o tsv | tr -d '\r')
export ARM_TENANT_ID=$(az account show --query tenantId -o tsv | tr -d '\r')
export ARM_USE_AZURECLI=true
2. Provider 역할 분리 ( azurerm & azuread )
Lustre의 스토리지 접근 권한을 설정하기 위해 서비스 주체(Service Principal)를 조회하는 과정에서 data "azurerm_service_principal"이 지원되지 않는다는 오류를 만났습니다.
- 기술적 배경: Terraform Provider 생태계가 발전하면서, 각 Provider는 자신의 전문 영역에 더 집중하도록 역할이 명확하게 분리되었습니다.
- azurerm: Azure의 핵심 인프라 자원(VM, 스토리지, 네트워크 등)을 관리하는 Azure Resource Manager (ARM) API와 통신합니다.
- azuread: Azure의 ID 및 인증 객체(사용자, 그룹, 서비스 주체 등)를 관리하는 Microsoft Graph API와 통신합니다.
- 해결책과 교훈: 이 문제를 해결하기 위해 프로젝트에 azuread Provider를 추가했습니다. 그리고 azuread_service_principal 데이터 소스를 사용해 Lustre 서비스의 ID 정보(object_id)를 조회한 후, 이 ID를 azurerm_role_assignment 리소스에 전달하여 인프라(azurerm)와 ID(azuread)를 연결했습니다.
3. 상태 관리 ( tfstate 파일 관리 )
Terraform의 가장 강력한 기능이자 가장 주의해서 다뤄야 할 것이 바로 상태 파일(.tfstate)입니다.
- 어려움: apply가 중간에 실패하자, Azure Portal에는 리소스가 남아있지만 .tfstate 파일에는 기록되지 않은 상태 불일치(Drift)가 발생했습니다. 이로 인해 Terraform은 다음 apply 시 "이미 존재한다"는 오류를 내며 작업을 거부했습니다.
- 기술적 배경: .tfstate 파일은 Terraform이 관리하는 인프라의 '설계도'이자 '관리 장부'입니다. Terraform은 작업을 시작할 때 항상 이 장부를 기준으로 실제 Azure의 상태와 비교하여 변경 계획을 세웁니다. 장부에 없는데 실제 세상에 리소스가 있으면, Terraform은 그것을 자신이 관리하지 않는 외부 리소스로 간주하고 충돌을 일으킵니다.
- 해결책과 교훈: 이 불일치를 해결하는 가장 확실한 방법은 두 세상(장부와 실제)을 다시 일치시키는 것입니다.
- 현실을 장부에 맞추기: terraform import를 사용해 현실의 리소스를 장부로 가져올 수 있습니다.
- 장부를 현실에 맞추기: terraform state rm을 사용해 장부에서 특정 기록을 삭제할 수 있습니다.
4. 버전 관리 및 보안 ( .gitignore)
인프라 코드를 Git으로 관리하는 것은 협업과 자동화의 첫걸음이며, 이때 보안은 가장 중요한 요소입니다.
- 어려움: tfstate 상태 파일등 Public Repo에 공유되면 안되는 정보들이 있습니다. IaC 테라폼 코드 공유를 진행하면서 보안상 노출되지 않아야하는 정보는 따로 관리할 필요가 있습니다.
- 해결책: .gitignore 파일은 프로젝트 생성 시 가장 먼저 설정해야 할 안전장치입니다. *.tfstate(모든 비밀 정보 포함)와 *.tfvars(환경별 민감 정보) 파일을 반드시 제외하여, 인프라의 모든 정보가 담긴 '마스터키'가 외부에 유출되는 것을 원천적으로 차단해야 합니다.
( 다만, 운영환경에서는 Cloud Storage (예: Blob)과 같은곳에서 관리하여 버전 관리 및 보안을 향상시키는게 맞다고 생각합니다.)
'Terraform' 카테고리의 다른 글
| [Terraform] 복잡한 조건문 (조건 분기) (4) | 2025.08.08 |
|---|---|
| [Terraform] 반복문 및 조건문 (2) | 2025.08.05 |
| [Terraform] 모듈 버전 관리 with Github (2) | 2025.08.04 |
| [Terraform] 테라폼 모듈 (2) | 2025.08.01 |
| [Terraform] 상태 파일(tfstate) 관리 (0) | 2025.07.31 |